


Payday loan online is an amazing opportunity to get your money in a snap 2022
A payday loan online is a modern financial service that provides loans to credit/debit cards in a matter of minutes. To get it, you don’t […]
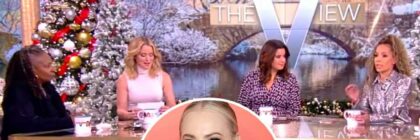
Meghan McCain Threatens Legal Action Against View Hosts After 'Defamatory and Slanderous' Accusations
"Not all politician's children are the same – and I am no Hunter Biden," McCain tweeted following Thursday's episode. Meghan McCain is slamming her former […]

My house is about to fall off a CLIFF and into the sea right before Christmas – the coastline is like 'cream cheese' | The Sun
A HEARTBROKEN mum fears her family home will fall into the sea by Christmas as she says the coastline is like “cream cheese”. Nicola Bayless's […]

My friend say I was assaulted but I don't think I was. Who's right?
My friend insists I was assaulted by one of our male pals who I had a drunken one-night stand with 20 years ago – I […]

Layton Williams pal Arlene Phillips tells critics to 'back off'
Strictly’s Arlene Phillips warns harsh trolls to ‘back off’ Layton Williams – as former pro James Jordan says it ‘isn’t right’ that the performer is […]





Telewizja polska online – tylko na PolBox.TV
W dzisiejszych czasach mnóstwo ludzi migruje z kraju do kraju, za lepszym bytem, pogodą, rodziną i z wielu innych powodów. I pewnego dnia, przychodzi moment, […]






